Motivation
Machine learning models are often deployed in highly dynamic environments, where the data distribution shifts unexpectedly over time. Traditional training assumes that test data follows the same distribution as training data—a fragile assumption that quickly breaks in real-world settings.
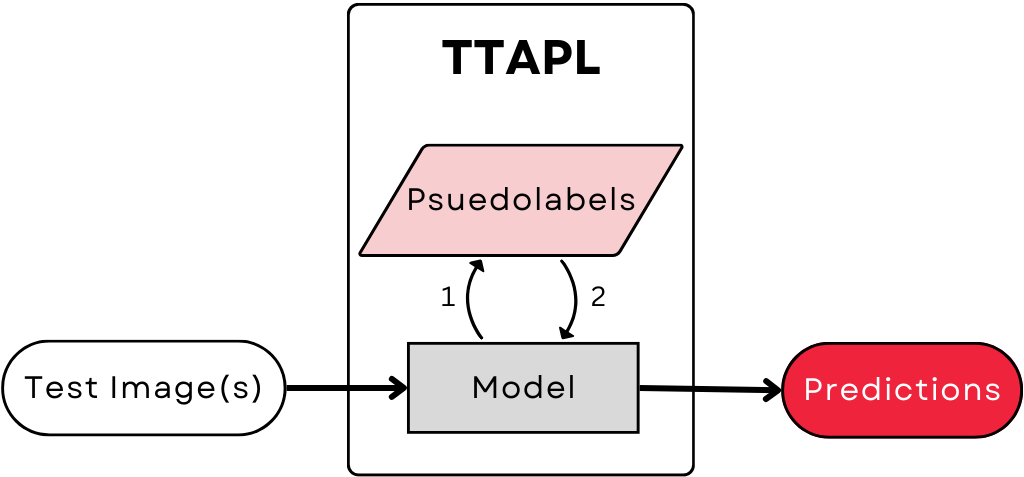
Test-Time Adaptation (TTA) tackles this challenge by adjusting models at inference time, without requiring new labels. A key approach is Test-Time Adaptation with Pseudo-Labeling (TTAPL), which leverages unlabeled test data to refine predictions. However, standard TTAPL can suffer from instability and error accumulation if pseudo-labels are inaccurate.
Our work is driven by the need to enhance TTAPL so models can better handle shifting data distributions over time. We investigate how alternative loss functions and architectural variations impact TTAPL performance, ultimately aiming to build models that remain robust and reliable across diverse deployment scenarios.
Background
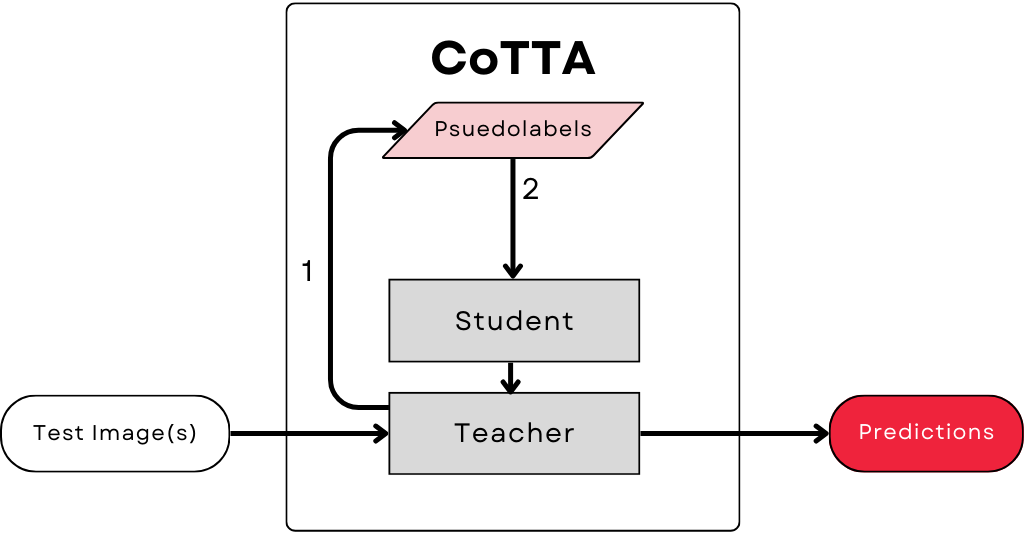
Continual Test-Time Adaptation (CoTTA) extends TTAPL by updating model parameters continuously with each new data point, rather than waiting for large batches of unlabeled data. CoTTA's approach typically includes:
- Consistency loss: Encourages stable predictions across augmented views of the same input.
- Teacher-student updates: A “teacher” model refines the “student” model iteratively, reducing catastrophic forgetting.
By blending self-training with cautious weight updates, CoTTA aims to preserve the model's original knowledge while adapting to new conditions. In practice, this can be challenging when the distribution shift is severe or the model architecture is especially large. Our research examines how different consistency losses (e.g., KL, PolyLoss, Cosine Similarity) affect CoTTA's ability to adapt across multiple architectures.
- Pseudo-label drift: Incorrect pseudo-labels reinforce model biases, leading to cascading errors.
- Overfitting to test samples: Excessive adaptation to a small set of test data can degrade model generalization.
Methods
Our evaluation of Continual Test-Time Adaptation (CoTTA) was conducted using the standard CIFAR-10-to-CIFAR-10C image classification task. CIFAR-10 consists of 60,000 32x32 color images across 10 classes, while CIFAR-10C is a corrupted version of the test set with severe distortions such as noise, blur, and digital artifacts.
In this task, a model's ability to correctly classify a large number of corrupted images reflects its capacity to adapt to distribution shifts. We tracked four key metrics—accuracy, precision, recall, and F1 score—to measure improvements relative to a baseline model that receives no adaptation.
Experiment Structure: For each combination of neural network architecture and consistency loss function, we ran the adaptation process on CIFAR-10C (Severity 5 corruptions only). This allowed us to isolate the effects of both model complexity and loss function choice on adaptation performance.
Model Choice: Our experiments used models selected from RobustBench, ensuring a diverse range of architectures. We evaluated variants of ResNet (PR), WideResNet (WR), and PreActResNet (R), including models that have been trained with robust strategies such as RLAT and AugMix. Models are labeled M1 through M7 in order of increasing depth and complexity, which helped us assess the influence of architecture on test-time adaptation.
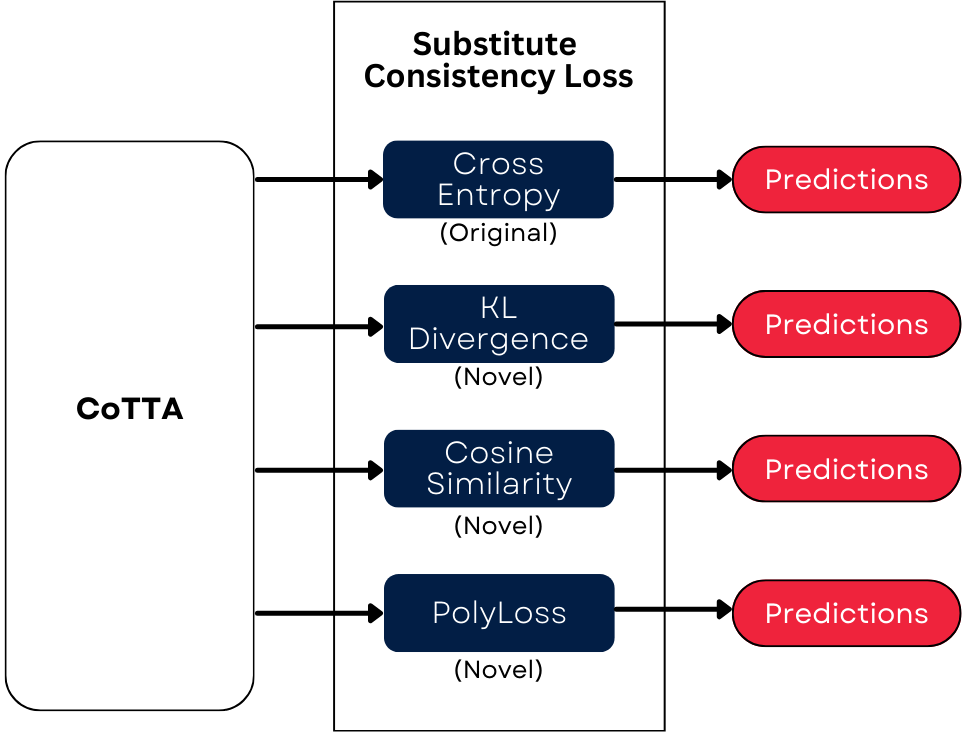
Loss Functions: In addition to a baseline with no adaptation and Normal TTA, we evaluated TENT (which minimizes entropy) and several CoTTA variants using different consistency losses:
- Cross-Entropy: Serves as our baseline since CoTTA was originally designed with CE loss.
- Cosine Similarity: Measures the angular difference between prediction vectors, potentially leading to smoother updates.
- PolyLoss: An extension of cross-entropy with a polynomial term (ε = 0.1) to reduce overconfidence.
- KL Divergence: Compares the full probability distributions between teacher and student, supporting gradual adaptation.
- Self-Training Cross-Entropy: Uses the student model's own predictions as pseudo-labels, though it may reinforce initial errors.
Our aim was to determine whether alternative loss functions can provide performance comparable to or better than the cross-entropy baseline, and to understand how different architectures respond under these various adaptation schemes.
Results
Our experimental results indicate that when model architecture is held constant, CoTTA variants using Cross-Entropy, KL Divergence, and PolyLoss deliver similar improvements across the key metrics—typically within a ±1% range.
This consistency suggests that the choice of consistency loss can be flexibly substituted without a drastic impact on overall prediction quality, provided the model architecture remains unchanged.
In contrast, when we fix the loss function, model architecture emerges as a critical factor. For example, models trained with robust methods like RLAT or AugMix often show significant improvements under CoTTA, whereas certain high-capacity models exhibit instability or even reduced performance relative to the source model.
Among the loss functions tested, CoTTA with KL Divergence and PolyLoss consistently matches or exceeds the performance of the cross-entropy baseline, while the self-training variant frequently underperforms. This disparity underscores the challenges of relying solely on self-generated labels in a continual adaptation framework.
Overall, our findings emphasize that no single TTA strategy is optimal across all scenarios. Instead, the effectiveness of test-time adaptation is governed by the interplay between the chosen consistency loss and the underlying model architecture. For a more detailed view of the numerical improvements, please refer to the interactive table below.
| Method | M1 | M2 | M3 | M4 | M5 | M6 | M7 |
|---|---|---|---|---|---|---|---|
| None | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Normal TTA | 5.08 | 9.45 | 2.83 | 23.08 | 4.72 | 9.46 | 3.78 |
| TENT TTA | 7.27 | 11.16 | 4.03 | 23.37 | 3.46 | -13.52 | 4.46 |
| CoTTA | 8.37 | 11.71 | 5.20 | 26.53 | 6.44 | -2.49 | 5.49 |
| CoTTA-Poly | 8.99 | 11.24 | 5.21 | 25.66 | 6.62 | -7.44 | 5.82 |
| CoTTA-KL | 8.32 | 11.70 | 5.22 | 26.58 | 6.45 | -2.58 | 5.51 |
| CoTTA-Cosine | 7.43 | 11.17 | 4.25 | 25.77 | 5.63 | -5.65 | 4.62 |
| CoTTA-SelfTrain | -3.06 | -17.67 | -30.70 | -1.74 | -15.06 | -45.56 | -14.34 |
Team Contributions
Ansh
Implemented two models, analyzed result metrics, contributed to website.
Ifunanya
Implemented two models, contributed to poster and paper.
Keenan
Restructured original CoTTA repository to run on different architectures, contributed to website.
Nick
Implemented two models, contributed to poster and paper.
References
- Goyal, Sun, Raghunathan, Kolter. "Test-Time Adaptation via Conjugate Pseudo-labels." Neural Information Processing Systems (NeurIPS), 2022. https://arxiv.org/pdf/2207.09640
- Wang, Fink, Gool, Dai. "Continual Test-Time Domain Adaptation." 2022. https://doi.org/10.48550/arXiv.2203.13591
- Hendrycks, Dietterich. "Benchmarking Neural Network Robustness to Common Corruptions and Perturbations." 2019. https://arxiv.org/pdf/1903.12261